`fmin_adam` 是来自 Kingma 和 Ba [1] 的 Adam 优化算法(具有自适应学习率的梯度下降,每个参数单独使用 Momentum)的实现。 Adam 设计用于处理随机梯度下降问题; 即当仅使用小批量数据来估计每次迭代的梯度时,或...
”梯度下降优化 Momentum NAG AdaGrad Adam“ 的搜索结果
无约束优化,最速下降法和共轭梯度法极小化函数
最详细的题目下降法代码_MATLAB编程-梯度下降法优化线性函数-梯度下降法求解多元函数最小值-注释详细
改进的最速梯度下降法,优于数值优化,matlab实现
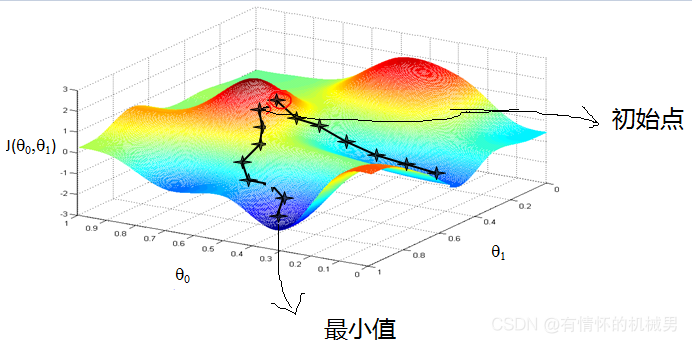
二次梯度优化的最陡下降法MATLAB程序
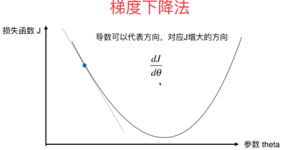
梯度方向是,步长设为常数Δ,这时就会发现,如果用在梯度较大的时候,离最优解比较远,W的更新比较快;在这儿,我们再作个形象的类比,如果把这个走法类比为力,那么完整的三要素就是步长(走多少)、方向、出发点...
本文档我学习梯度下降优化算法的总结,开头是深度学习的基本介绍,了解为什么要用梯度下降算法,以及传统的梯度下降算法的弊端,后面的主要章节是从momentum和adaptive两方面,进行梯度下降优化算法的展开,有详细的...

梯度下降优化算法综述 梯度下降优化算法综述 梯度下降优化算法综述
对数几率回归(Logistic Regression),又称为逻辑回归的python实现,并且通过梯度下降法进行优化
梯度优化器通常描述比较晦涩难懂,本文将常见优化器分类总结,清晰易懂
采用梯度下降法,优化弯道路径,可实现良好的弯道参考路径
损失使用平方函数,简单的线性模型 y = theta1 + theta2 * x
梯度下降优化算法总结
标签: 优化算法
梯度下降(Gradient descent)算法可以说是迄今最流行的机器学习领域的优化算法。并且,基本上每一个深度学习库都包括了梯度下降算法的实现,比如Lasagne、cafe、keras等。关于梯度优化的三种分类在机器学习中常用的...

常见的最优化方法有梯度下降法、牛顿法和拟牛顿法、共轭梯度法等等,本文主要介绍牛顿法和梯度下降法原理以及使用Python编程应用问题。 二、应用领域 使用牛顿法或梯度下降法,在最优化算法所解决的问题中,有着很...
深度学习之梯度下降与优化
标签: 深度学习


基于LR的优化方法:梯度下降法,随机梯度下降法,牛顿法,LBFGS,BFGS.zip
此代码包括牛顿法和梯度下降法的实现过程,最优化以及算法中常见的问题解决方式
一、梯度下降法 重申,机器学习三要素是:模型,学习准则,优化算法。这里讨论一下梯度下降法。 通常为了充分利用凸优化中的一些高效成熟的优化方法...机器学习中,常用的优化算法就是梯度下降法,首先初始化参数θ0...
深度学习框架(例如:TensorFlow,Keras,PyTorch)中使用的常见梯度下降优化算法。梯度下降是一种用于寻找函数最小值的优化方法。它通常在深度学习模型中用于通过反向传播来更新神经网络的权重。 VanillaSGD 朴素...
梯度下降优化算法Momentum
标签: 算法
Momentum算法在原有的梯度下降法中引入了动量,从物理学上看,引入动量比起普通梯度下降法主要能够增加两个优点。首先,引入动量能够使得物体在下落过程中,当遇到一个局部最优的时候有可能在原有动量的基础上冲出这...
全梯度下降算法(FGD)、随机梯度下降算法(SGD)、随机平均梯度下降算法(SAGD)、小批量梯度下降算法(Mini-batch gradient descent,MGD)梯度下降优化算法,动量法、Adagrad、Adadelta、RMSProp、Adam
最近在学习《机器学习实战:基于Scikit-Learn和TensorFlow》,这里把之前的一些基础知识点进行了总结。 对于一个线性函数: y^=hθ(x)=θ⋅x\hat{y}=h_{\theta}(\mathbf{x})=\boldsymbol{\theta} \cdot \mathbf{x}y^...
推荐文章
- javafx预览PDF_javafx pdf-程序员宅基地
- ipv4与ipv6访问_纯ipv4访问纯ipv6-程序员宅基地
- css强制换行-程序员宅基地
- 链霉亲和素修饰的CdSe–ZnS量子点-程序员宅基地
- 饿了么4年 + 阿里2年:研发路上的一些总结与思考-程序员宅基地
- vue的sync语法糖的使用(组件父子传值)_sync传值-程序员宅基地
- 最大流最小割_网络最大流量与割的容量的关系-程序员宅基地
- queryString模块_querystring模块安装-程序员宅基地
- 安卓电量检测工具Battery Historian的使用记录_battery-historian 电量测试-程序员宅基地
- 基于QPSK的载波同步和定时同步性能仿真,包括Costas环的gardner环_qpsk符号同步-程序员宅基地